In this page
Save PDF documents to the filesystem from a JQL query on a specified schedule
Save PDF documents to the filesystem on issue events (created, updated, commented, etc.)
Save PDF action parameters
How to generate and save PDF documents from Jira to the filesystem?
Automatically generating PDF files and saving them to the Jira server filesystem is an easy way to take snapshots about your Jira issues for auditing, archiving and integration purposes.
You can implement this process by configuring a simple automation rule:
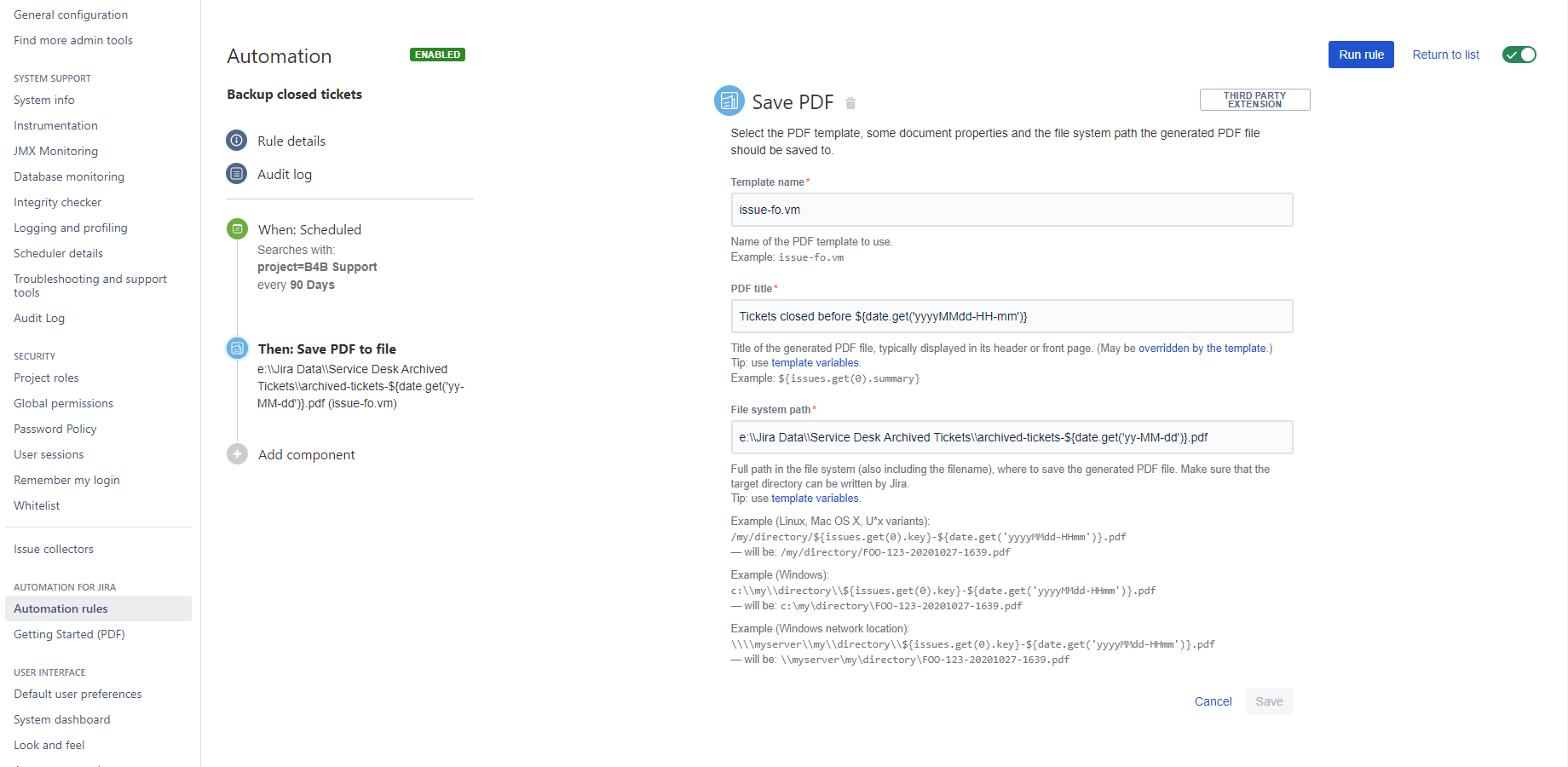
Every time the rule is executed, the PDF file will be saved to the file system:
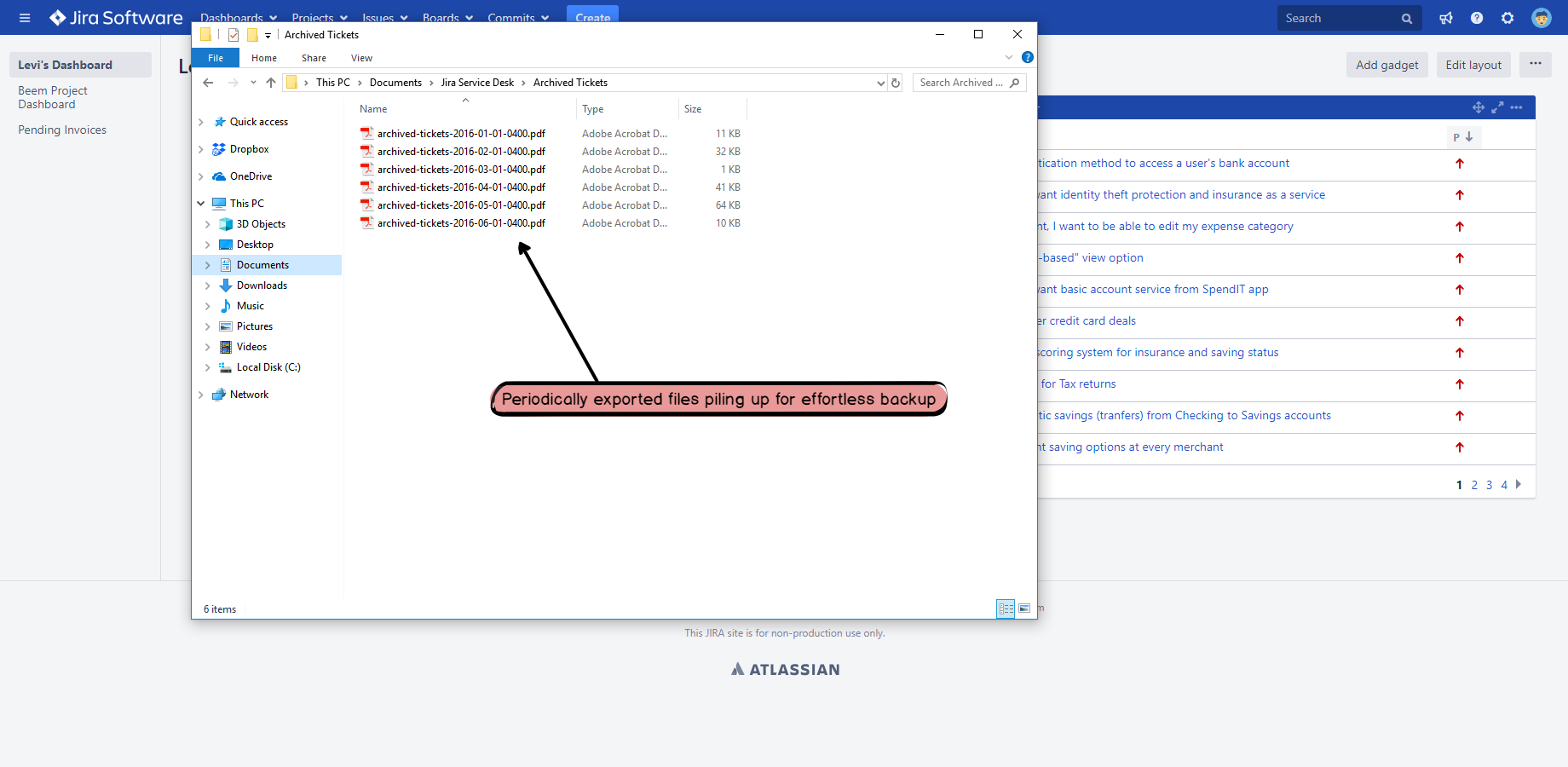
To have this in minutes, just follow the step-by-step guides in the next sections!
Notes:
- Although the guides are written specifically for the Scheduled and the Issue Event (created, updated, etc.) triggers, you can choose any other trigger!
- Although the guides are written to implement the "bare minimum" rules, you can freely add further actions or conditions for altered logic!
- The email with the PDF file attachment is sent from the "no-reply@jpdfc.midori.systems" address. This is a verified email address and cannot be changed due to security reasons.
Save PDF documents to the filesystem from a JQL query on a specified schedule
Configuration steps:
-
Follow the same steps as in the Send PDF document on a specified schedule guide with the following differences:
- In step 12, select and configure the Save PDF Action (action parameters).
- You're done!
Save PDF documents to the filesystem on issue events (created, updated, commented, etc.)
Configuration steps:
-
Follow the same steps as in the Send PDF document on a specified schedule guide with the following differences:
- In step 4-9, select and configure the Multiple issue events trigger.
- In step 12, select and configure the Save PDF Action (action parameters).
- You're done!
Save PDF action parameters
The File system path parameter determines the full file system path (including the filename, too) where to save the generated PDF document. You can freely use local paths, network paths and drives here. See these examples:
## for Linux, Mac OS X, U*x variants:
/my/directory/${issues.get(0).key}-${date.get('yyyyMMdd-HHmm')}.pdf
## ...will result in the path: "/my/directory/FOO-123-20141027-1639.pdf"
## for Windows "regular" paths:
## (note the double backslash characters used for escaping!)
c:\\my\\directory\\${issues.get(0).key}-${date.get('yyyyMMdd-HHmm')}.pdf
## ...will result in the path: "c:\my\directory\FOO-123-20141027-1639.pdf"
## for Windows network locations:
\\\\my-server\\my\\directory\\${issues.get(0).key}-${date.get('yyyyMMdd-HHmm')}.pdf
## ...will result in the path: "\\my-server\my\directory\FOO-123-20141027-1639.pdf"
Tips for advanced use cases:
- Saving the PDF file to a remote location that requires authentication: just map it as a network drive with the proper login credentials, then configure the action to write to the resulted drive.
- Saving the PDF file to the cloud: see the cloud integrations page with guides for Dropbox, Google Drive and Microsoft OneDrive.
Avoid these typical problems:
- Make sure that the target directory can be written by the Jira process.
-
If you use an expression in the File system path parameter, make sure that it will not result in characters that would break the resulted path.
For example, it is safe to use the key field of the issue in the expression, because Jira issue keys can contain alphanumeric characters and '-' only, and all those are allowed in paths. In contrary, the summary field can contain nearly any character, some of which are not allowed in paths! Note that the disallowed characters in paths depend on your operating system.
Similarly, if a summary like "Crash with low/zero memory" contains the path separator character ("\" on Windows and "/" on Linux), it will be rendered to the final path as "/my/directory/Crash with low/zero capacity.pdf", and there will be unexpected directories created.
To avoid these kind of problems, use an expression like this to replace the dangerous characters with '-':/my/directory/${issues.get(0).summary.replaceAll("[^\w- ]", "-")}.pdf -
If your rule is triggered multiple times and it exports to the same path, then the file will be overwritten every time.
If this is unwanted, include the timestamp in the filename to get a unique path at each export:
/my/directory/myexport-${date.get('yyyyMMdd-HHmmss')}.pdf
Questions?
Ask us any time.