
In this page
How does it work?
Archiving strategies
How strategies work
Creating archive spaces
Setting archive spaces to the "Archived" status
Archiving pages with the Move strategy
Copying ancestor pages
Synchronizing ancestor pages
Moving pages
Archiving pages with the Copy and Trash strategy
Comparison of strategies
What is the best strategy for me?
Filtering labels
Disabling notification emails
Fixing links pointing to archived pages
Using archive spaces
Restoring archived pages
Permissions for restoring pages
Archiver user (actor)
Archiving policy
Using labels to control page archiving
Notification emails
About skipped pages
What is page archiving?
Page archiving helps to remove outdated Confluence pages from the view of your users. A page can become subject to archiving in three ways:
- It was not updated for N days.
- It was explicitly marked for archiving by the "archive" or "archive-single" label added.
- It was assigned a specific archiving date (like "2018/05/23") and that date was passed.
Archiving the pages that are not needed anymore (instead of permanently deleting them) is crucial to preserve the precise history of your content yet to keep current content lean and consistent.
How does it work?
You can activate page archiving by checking the If the page is not updated for N days option, the If the page is not viewed for N days option, the Labeled with 'archive' or 'archive-single' option, or their combination in the lifecycle configuration settings.
Please note that although the "notify" actions are optional, the "archive the page" action is always active. Simply because it makes no sense to turn that off. If you want to inactivate this feature, then just uncheck all triggers.
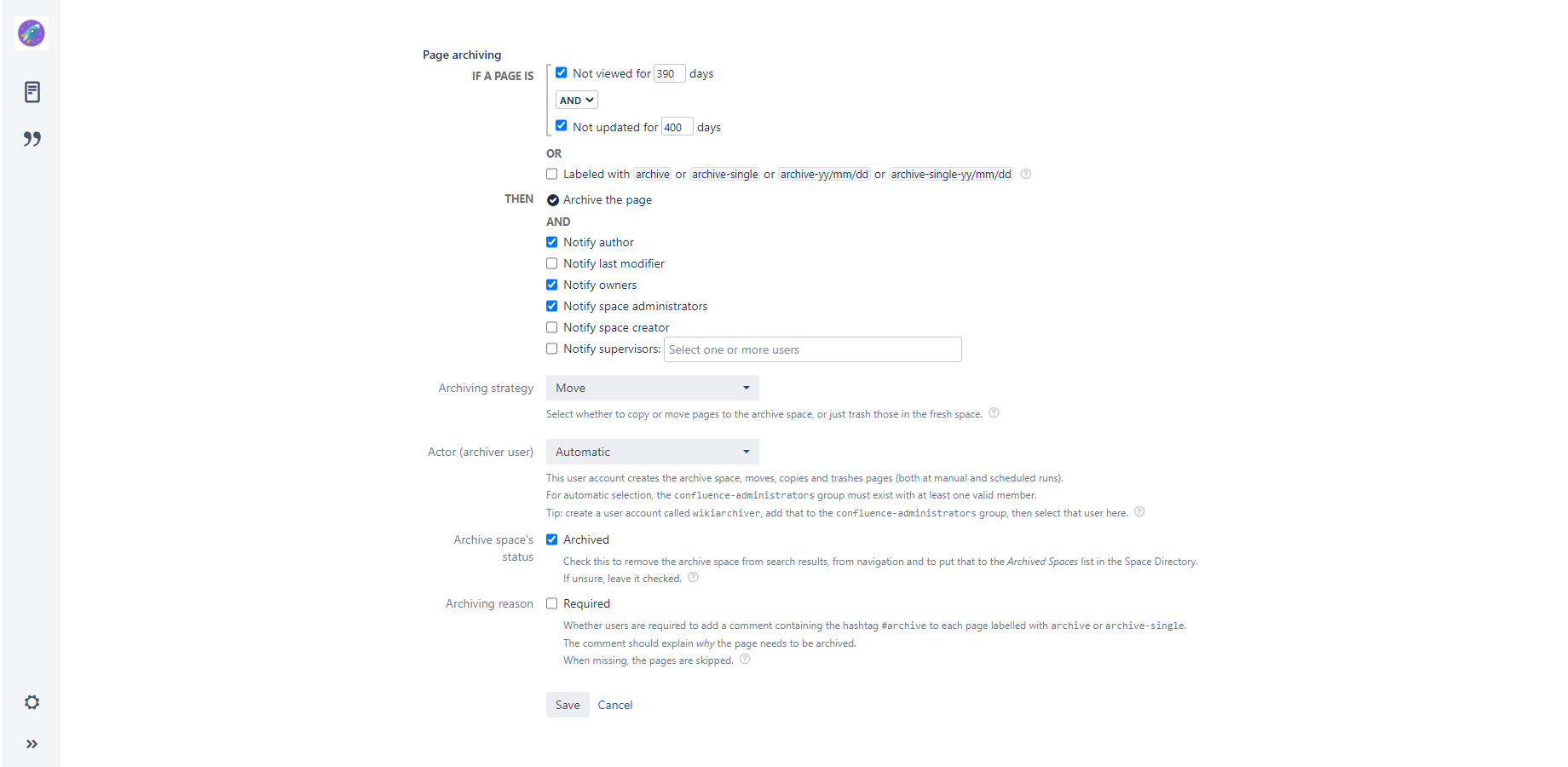
When the content lifecycle job is executed:
- The app calculates the age of each page and compares that to the archiving limit value.
- It checks if there are "archive" or "archive-single" labels added to the page.
- It also checks if there are "archive-yy/mm/dd" or "archive-single-yy/mm/dd" format labels added to the page. If there are, it takes the earliest data and compares that to the current date.
If a page matches any of these criteria, it becomes subject to archiving.
Archiving strategies
After the pages that should be archived were found, this is the archiving strategy that does the actual archiving work. In other words, the strategy defines what will happen to the archivable pages during the archiving process.
The feature to select between archiving strategies is available since Better Content Archiving version 5.1.0. In pre-5.1.0 versions there is only the strategy called Copy and Trash available (hard-wired). Thus, archiving configurations created in pre-5.1.0 versions will be migrated to use the Copy and Trash strategy when the app is updated to 5.1.0. We think that Move works better in most cases, therefore you should consider switching to that after the version update.
Strategy is an option in the archiving configuration, allowing you to select that separately for each space via custom configurations, or select that consistently via global configurations.
There are three strategies available (since 5.1.0), each having its own merits:
- Copy and Trash: This replicating strategy copies the pages to the archive space, and trashes them in the original space.
- Move: This replicating strategy moves the pages to the archive space. (This is the default strategy.)
- Trash: This strategy simply trashes the pages. (This strategy does not create an archive space.)
Or, you can implement a fourth strategy Permanently delete by combining Trash with periodical purging.
To find out which strategy fits your use case the best, see the comparison of strategies and the selection guide.
How strategies work
As mentioned above, the Trash is the simplest strategy: it deletes the pages to archive. This has the same semantics as manually deleting a page: that will reside in the trash of the fresh space, until the first emptying. In this sense, this strategy is not about actual archiving, but about removing clutter and about releasing storage easily and quickly.
Copy and Trash and Move are, in contrast, so-called replicating strategies. It means those will either copy or move the pages to the corresponding archive space, taking care of "replicating" (reproducing) the fresh space's page structure also in the archive space. The picture below shows how the fresh space and the archive space will look after archiving a tree of 4 pages rooted at Helpdesk Reports.
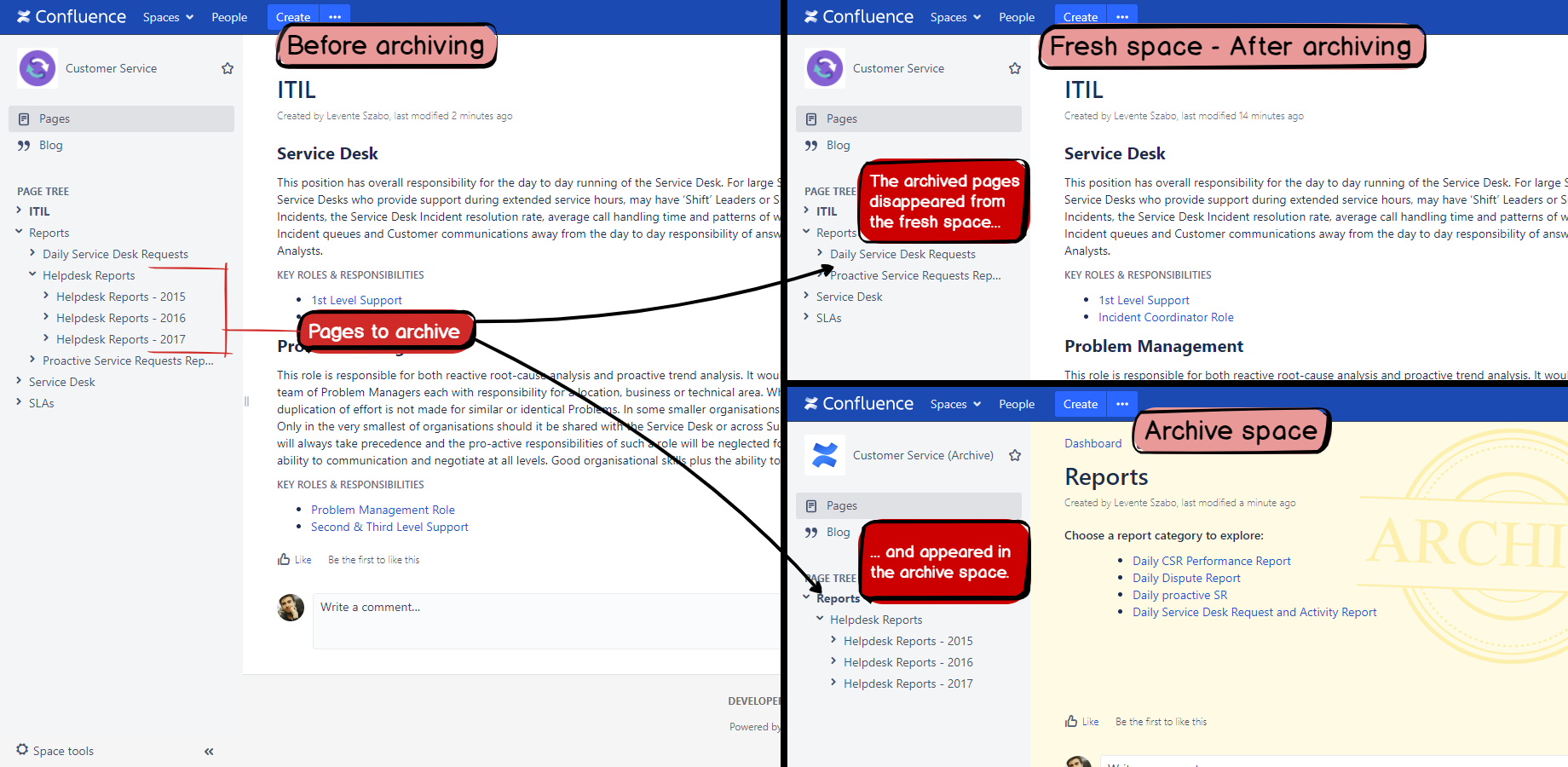
The following section explains the details what happens when a page is being archived using one of these two strategies.
Creating archive spaces
When the first page to archive is found, a new Confluence space (the so-called archive space) will be created as the new home of the archive pages. Its space key will be "<fresh space key>Archive" and its name will be "<fresh space name> (Archive)". If that space already exists due to prior archiving executions, then the existing space will be used.
As for security, all read-type space permissions will be copied from the fresh space to the archive space. To be more specific, the following permissions are the ones that are not copied:
- Write-type permissions, like edit page or add comment. The idea is to discourage making updates in the archive space.
- Anonymous permissions. The idea is that even if the fresh space was open for anonymous readers, the archive space should not be. (since app version 8.2.0)
- "All authenticated users" permissions. (since app version 8.2.0)
Although it is considered an unusual practice, space administrators can re-add these permissions to the archive space later if needed. They can use the standard Confluence feature for that.
Setting archive spaces to the "Archived" status
If you check the Archived option at Archive space's status in the archiving configuration, the archive space will be set to the "Archived" status. (In pre-7.3.0 app versions the same option is called Hide the archive space, but it works identically.)
This space status will remove the archive spaces and their contents from search results, navigation, dashboards and activity streams - practically hiding them. It will also put the archive spaces to the Archived spaces list in the Space Directory - where they'd be expected. For more details on the effects of the "Archived" space status, see this article in the Confluence documentation.
We strongly suggest checking this option. Otherwise, the archive space will be set to the "Current" status, making that a "regular" space. It may result in confusion:
- Your users may receive duplicated search results: one from the fresh and the other from the archive space.
- Your users may see the pages that are located in the archive space in activity streams.
- Your users may "get lost" while navigating: they will see both the fresh and the archive space, containing similar and overlapping content.
Overall, it is very intuitive to use the "archived" status for archive spaces.
Archiving pages with the Move strategy
This is the most frequently used strategy. As written above, it is a replicating strategy which reproduces the page hierarchy of the fresh space also in the archive space. The details of this are explained in the next sections.
Copying ancestor pages
Before actually moving a page, the strategy makes sure that its original position can be reproduced also in the archive space.
For this, the strategy replicates the page's branch to the archive space, from the root level to the page's parent. For example, if the page "X" was originally located at "Home"/"A"/"B"/"X", then "Home", "A" and "B" will be copied to the archive space, before "X" is moved. Note that although the page to archive is moved, its ancestors are copied, for obvious reasons.
When copying an ancestor, only its current state is copied. It includes its current version, current attachments, current comments and current labels. Copying only the current state is sufficient to keep the page hierarchy and it also saves storage.
Synchronizing ancestor pages
If an ancestor already exists in the archive space, because it was created by a previous archiving run, the strategy checks if it still accurately represents its fresh version.
It compares the page content, attachments, comments and labels between those. If differences are found, those are automatically "synchronized". As result, the ancestor is updated to the current version, current attachments, current comments and current labels of the fresh version.
The motivation is to keep the ancestor pages in the archive space identical with their correspondents in the fresh space.
Moving pages
After preparing its ancestor pages, the page to archive is moved to the archive space.
This "move" operation works similarly to manually moving a page:
- The page keeps its complete meta-information (versions, comments, attachments, labels, etc.) in the archive space.
- After the page was moved, its children are moved one level higher in the fresh space's page tree.
Archiving pages with the Copy and Trash strategy
Using the Copy and trash strategy works similar to Move (see the previous section) with the following notable differences:
- Pages are copied (instead of moved) to the archive space. The current page version is copied, together with the page permissions, comments, attachments and labels.
- After copying it, the original instance of the archivable page is trashed (deleted) in the fresh space.
The children of the archived pages are moved one level higher, just like with Move.
The replication of the ancestors works the same as with Move.
Comparison of strategies
| Copy and trash | Move | Trash | |
|---|---|---|---|
| Archive space | Created when archiving the first page | Created when archiving the first page | Not created |
| Page versions | Only the latest version kept (only the most current page version is copied, although additional runs synchronize that) |
All versions kept | Deleted (precisely: all versions kept in the trash until that is emptied) |
| Attachments | Only the latest version kept | All versions kept | Deleted (precisely: all versions kept in the trash until that is emptied) |
| Comments | Archived | Archived | Deleted (precisely: kept in the trash until that is emptied) |
| Labels | Archived | Archived | Deleted (precisely: kept in the trash until that is emptied) |
| Incoming links to archived pages | Will turn into "create page" links (as the linked page was trashed) |
Will not change (but will point to the pages in the archive space, which are accessible only by administrators) |
Will turn into "create page" links (as the linked page was trashed) |
| Performance | Slow | Faster (in most cases) |
Very fast |
| Storage requirements | Temporarily doubled (emptying the trash releases the "duplication", and storage will equal to the original) |
Unchanged (deleting the archive space releases the storage required by the archived content, but restoration won't be possible anymore) |
Unchanged (emptying the trash releases the storage required by the archived content, but restoration won't be possible anymore) |
| How to restore an archived page? |
Restore from the trash if that wasn't emptied yet.
It restores all details (history, attachment versions, etc.), but only works for individual pages (inconvenient for many). Alternatively, move back from the archive space (together with its descendants). It is more convenient for bulk restoration, but page history will be lost (as that was not archived originally). Read about the permissions required. |
Move back from the archive space (together with its descendants). It is convenient and will keep all page details (including page versions). Read about the permissions required. | Restore from the trash if that wasn't emptied yet. It restores all details (history, attachment versions, etc.), but only works for individual pages (inconvenient for many). |
What is the best strategy for me?
Use Move:
- Unless you have strong arguments toward the two other strategies, use Move. (We have chosen this for the default, because we think this fits the typical use cases the best.)
Use Copy and Trash:
- If you don't want to keep all versions of the pages and attachments to archive, only the most current one, then it is more efficient than Move. It requires less space and it may be faster, at cost of not keeping the full history of pages and attachments.
- If you are a long-time user of Better Content Archiving, and your team already understood the semantics of archiving in pre-5.1.0 app versions, you may want to stay with this strategy.
Use Trash:
- If your primary concern is freeing up storage, cleaning up your spaces and improving your Confluence's performance.
- If you are totally sure that you will not need the old pages anymore (ex: you know that that is just garbage piled up over the years).
Note: use the Empty trash feature to permanently release the storage, but consider making a backup before that. You can automate emptying the trash using this recipe.
Filtering labels
Labels are used for various mechanisms in Confluence. When a page is moved or copied to the archive space, its labels are filtered to avoid unexpected behavior.
The following labels are removed by the filter in the archive space:
- All labels that control the Better Content Archiving app. These simply do not make any sense in the archive space. Plus, if you would restore a page that still has the archive-single label, for instance, then it would be re-archived at the next execution of the archiving process.
- The my:favourite and my:favorite labels are used to mark your favourite pages. These are removed to keep your favourite list clean (after moving a page to the archive space) and to avoid duplicated entries in the favourite list (after copying a page to the archive space).
All other labels are kept without changes in the archive space.
Disabling notification emails
The operations executed during archiving would normally result in sending out a lot of notification emails, about page creations, moves, deletions, comments, attachments and mentions. This could possibly cause some confusion and unwanted email flood for users. Better Content Archiving for Confluence reduces this "noise" by simply not sending any of those built-in notifications.
The app's own notifications will be, however, sent to everyone configured in the archiving rules.
Fixing links pointing to archived pages
Links pointing to the archived pages will break, obviously. Either because the page is now in an archive space (Move) or because the page is trashed (Copy and Trash and Trash). Broken links clearly indicate that pages referring to the expired content must be updated, too.
At this point you may want to:
- remove the broken links in the referring pages, and rework the content around it,
- or restore the archived page from the Trash, and update its content to make them up-to-date again,
Note: Better Content Archiving does not hide or fix the broken links, by design, as that requires the content owner's intelligence.
Using archive spaces
Better Content Archiving applies a clear, but non-obtrusive style to archive spaces, to differentiate those from their fresh counter-parts. (since app version 7.2.0)
It includes a yellowish background color plus an expressive watermark:

This distinct style is visible both on the wiki pages and in the space's administration screens. The primary aim is to make it clearly visible that the user is in an archive space's context. When they understand the context, they will not make "accidental updates", post comments, etc. on the archived content (even if they had the permissions, which is unlikely anyway).
Other than the visuals, archive spaces are regular spaces in the sense that all Confluence core features are available on those. Note, however, that only a sub-set of the features makes sense in archive spaces.
You will typically:
- search for archived content
- view archived pages and attachments
- view the version history of archived pages (audits)
- restore archived pages and attachments
On the contrary, you are not likely to:
- create, edit, delete or otherwise make changes to archived content
Restoring archived pages
The way to restore an archived page depends on the strategy which was used to archive it. It is explained in the strategy comparison.
Permissions for restoring pages
In most situations when restoring pages, the page actually needs to be moved back from the archive space to the fresh space. The permissions required for this may not be intuitive, here is some explanation.
"Move page" requires the following permissions, without which the "Move" operation will not be offered for the user:
- "Add page" and "Delete page" permissions in the archive space.
- "Add page" permission in the fresh space.
The problem is that when the archive space is created, only read-only permissions are copied from the fresh space to the archive space, which excludes the two permissions at point 1. Therefore, "Move page" is not available in the archive space out of the box.
Solution: give the two permissions temporarily to the user who wants to restore archived pages. We strongly suggest to revoke these permissions after not needed anymore, because it is safer to disallow modifying the archive space. (Or, give these permissions permanently to the administrators of the archive space, enabling them to restore pages any time.)
Archiver user (actor)
As you have seen seen in the previous sections, archiving includes creating archive spaces and creating, moving, deleting pages. All these operations require a valid Confluence user account with the sufficient permissions.
As archiving is typically executed as a background job, when there is no "currently logged-in user" available, you are required to pre-select a Confluence user (also referred as "archiving actor") in the archiving configuration, on whose behalf all operations will be executed. Technically speaking, when the background job processes a space, it takes the actor that is selected in archiving configuration applied to that space, and "logs in" that user account. When the processing is done, the user gets automatically "logged out" from the job's thread. All this is totally transparent and has zero side-effect.
When editing an archiving configuration, the app offers all user accounts from the confluence-administrators group as an option for "archiver user". Although this special group is automatically created by Confluence, in some cases this is renamed to a different name (not recommended!), therefore the app will not be able to offer any option for actor. Make sure that this group exists and has at least one valid member.
There is also a fallback option called "Automatic", which should rarely be used. When you select this, the app will automatically search for a user account that could be used. Please note however that it is not guaranteed that the app will find the same user account every time, which may confuse some.
As a best practice, we suggest selecting a specific user account, and not relying on the automatic selection. We also suggest creating a separate user account with a descriptive name like "Wiki Archiver" for this, as that eliminates confusion. When other users see it in notification emails and activity streams, they will better understand what was going on.
Archiving policy
It is a very good practice to require the exact reason to be specified when someone wants a page to be archived. The app can enforce this if you check the Archiving reason required option when configuring.
If this option is activated, then the app will check if the archiving reason is defined for each page marked for archiving (using the labels). How to define the reason? Users must add a comment to the page, with the comment text containing the "#archive" hashtag. For example, this is a valid comment to describe the archiving reason: "This product was removed from the market last year. #archive".
If no such comment has been added, then the page will be skipped (will not be archived), and it will be reported to the user who originally added the label, so that he can fix the situation. If the comment is there, then the archiving will be executed normally, and the reason text will be reported in the notification emails, so that all stakeholders can clearly see it.
Important: age-based archiving does not use this option. If a page is to be archived due to its age exceeding the "archiving period", then no reason is required.
Using labels to control page archiving
Use the following labels:
| archive | Add to each page that you want to archive, together with the tree of its descendant pages. |
|---|---|
| archive-single | Add to each page that you want to archive, but leaving its descendants untouched. (This is the non-recursive version of archive.) |
| archive-yy/mm/dd | Add to each page that you want to archive on a specific date, together with the tree of its descendant pages. "yy" denotes the year, "mm" the month and "dd" denotes the day part of the date. Example: archive-16/2/25 archives this page on 25 Feb 2016. (since 4.5.0) |
| archive-single-yy/mm/dd | Add to each page that you want to archive on a specific date, but leaving its descendants untouched. (This is the non-recursive version of archive-yy/mm/dd.) (since 4.5.0) |
| archive-review | Add to each page that you want to mark for review. These will be listed in a separate category called To review, after they expire. You find this category under Space Tools → Archiving → Content Quality, then click on the expired pages count. (Not recursive.) |
| archive-update | Add to each page that you want to mark for update. These will be listed in a separate category called To update, after they expire. You find this category under Space Tools → Archiving → Content Quality, then click on the expired pages count. (Not recursive.) |
| noarchive | This label excludes a page, and all its descendants, from archiving. Note that this label excludes them from every mechanism: from page view tracking, from page expiration tracking and from page archiving! |
| noarchive-single | This label excludes a single page, but not its descendants, from archiving. (This is the non-recursive version of noarchive.) |
Notification emails
After the archiving was completed, the notification emails show you the archived pages with the reason why they were archived (expired, marked for archiving, etc.). The links point to the archived version of the pages, which can be used to view or restore content if needed later.
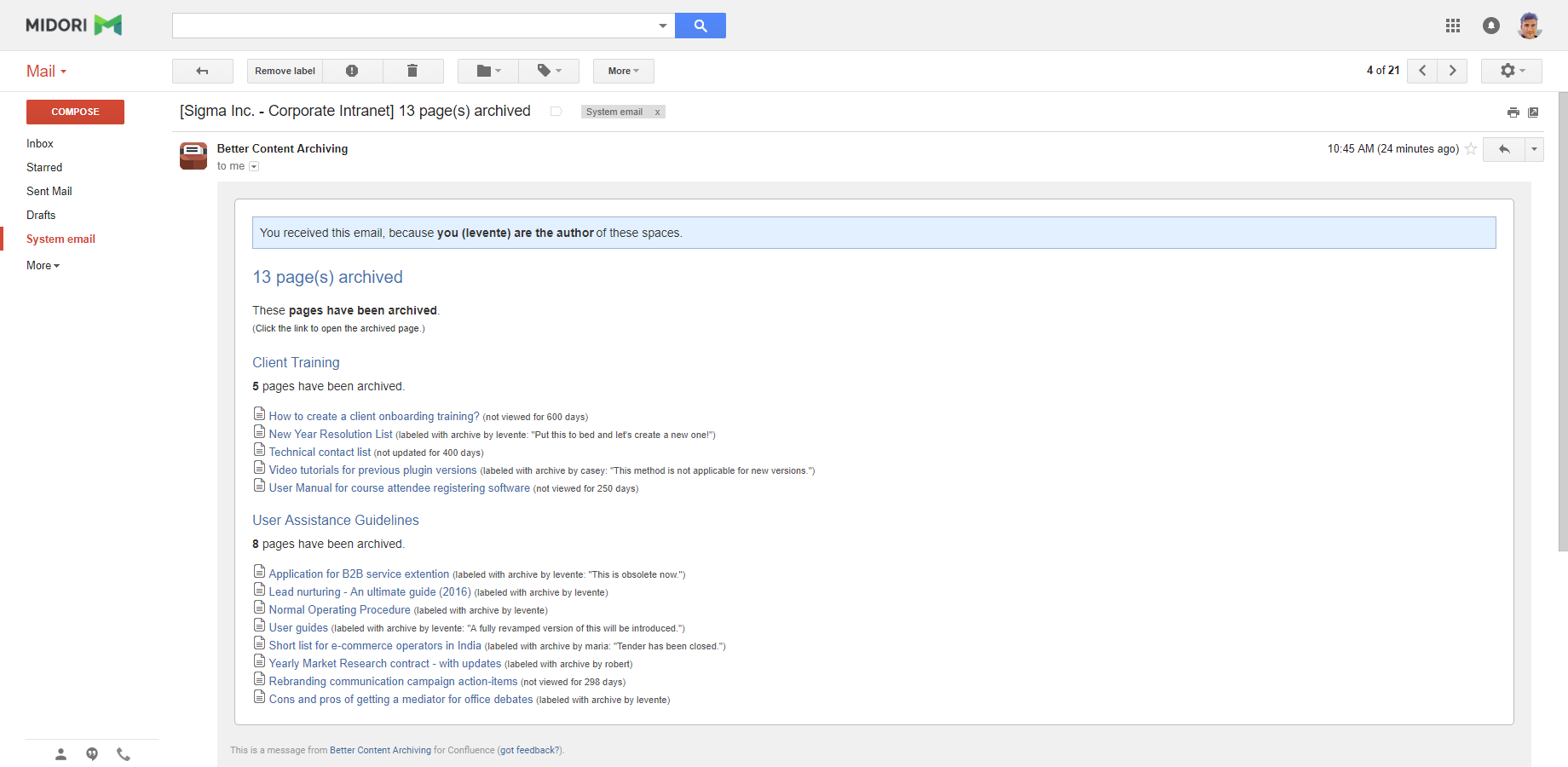
To reduce email traffic, a single email will be sent per user. It contains the full page list combined from all spaces where the user was selected to be notified.
About skipped pages
In spaces with archiving policy activated, the users, who marked the pages with the "archive" or "archive-single" labels, are warned when they forgot to specify the reason for archiving.
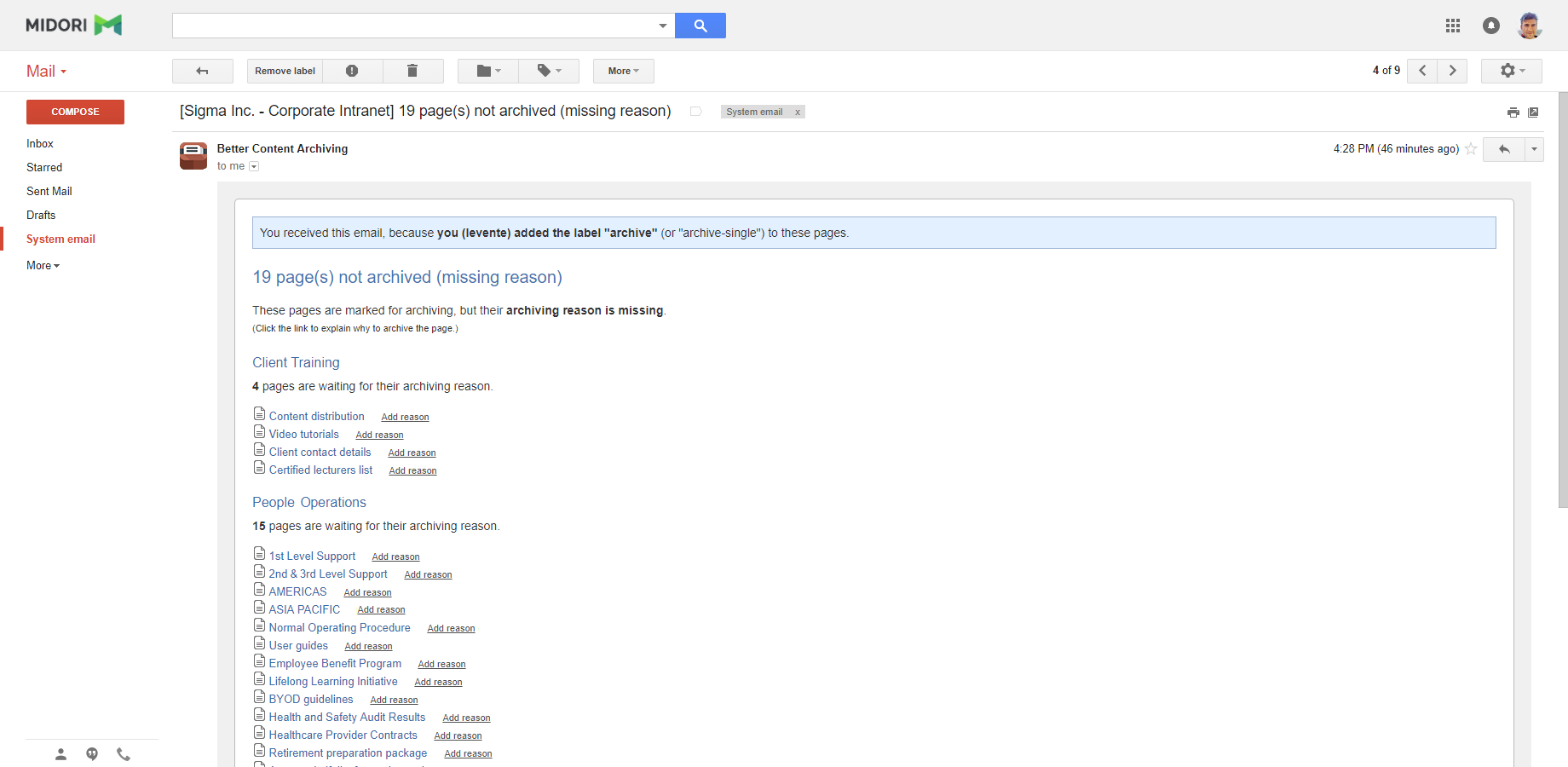
The emails provide quick links to add the missing page comments where the reason can be described.